增加数据传输容量的指尖大小光学模块光学I/O核心及其在FPGA中的应用
这里有东西被加密了,需要输入密码查看哦。
REF: A 64Gb/s Si-Photonic Micro-Ring Resonator Transceiver with Co-designed CMOS Driver and TIA for WDM Optical-IO,2024.10 - QiNan,2024 IEEE BiCMOS and Compound Semiconductor Integrated Circuits and Technology Symposium (BCICTS).
本文展示了一种混合集成硅光子(SiPh)收发器芯片组,用于封装内的光学I/O。在发射器中提出了一种双段微环调制器(MRM)和共同设计的驱动器,其中主路径和预加重路径分别优化以实现更高的总带宽。驱动器采用不对称电感峰化来补偿MRM的非线性。接收器采用级联环形谐振器(CRR)实现高Q值和宽通带滤波,用于波分复用(WDM)。高速度CMOS TIA与集成波长调谐共同设计。2D光栅耦合器和双向输入光探测器实现了偏振不敏感的光接收。实验结果表明,所提出的SiPh发射器在64Gb/s下实现了3.2dB的消光比(ER),并可达到最高70Gb/s的传输速度。接收器在64Gb/s速度下,实现了4.5ps的RMS抖动,在7dBm光输入时接收比特错误率(BER)达到了10^-12。
随着人工智能(AI)和机器学习(ML)的蓬勃发展,对高速数据通信的需求急剧增加。光学I/O将硅光子(SiPh)TRX集成到xPU封装中,使高密度、功率高效的光纤通道能够直接连接到芯片边缘。微环谐振器具有微米级的紧凑尺寸、小电容负载和天然波分复用(WDM)能力,使其特别适合于光学I/O链路。先前的研究已经展示了每通道数据速率高达16 Gb/s的SiPh MRM TRX。此外,PAM-4调制在数据速率加倍的同时会导致BER恶化(或过多的FEC延迟),并需要耗电的线性驱动电路。前馈均衡(FFE)用于解决与高速MRM驱动相关的带宽限制问题,但它引入了额外的寄生元件,且未能充分解决MRM的动态非线性效应。非线性通过额外的驱动结构得到缓解,但这也增加了功耗开销。
在本文中,我们研究了用于低延迟WDM光链路的64Gb/s NRZ每波长硅光子(SiPh)收发器,其创新之处在于:(1) 双段MRM和共同设计的驱动,解耦了驱动和FFE均衡,以优化驱动带宽,并采用了不对称电感器来缓解MRM的非线性效应;(2) 极化分离光栅耦合器(PSGC)和双向PD及其共同设计的TIA,能够实现对极化不敏感的接收。CRR在低串扰和高带宽的情况下促进了WDM的过滤。
图1展示了所提出的硅光子(SiPh)收发器的系统框图。在发送器(TX)中,微环谐振器被划分为两个长度不等的段。每个段都配备了一个专用驱动阶段,分别专注于驱动和FFE均衡。在较长的段上,驱动阶段输出1.8 Vpp的差分驱动电压,通过片上交流耦合单独驱动微环的PN结电极。此驱动阶段被简化以确保其在没有其他寄生元件的情况下提供充足的驱动能力。在另一个段上的驱动器配备分数UI延迟FFE,为信号提供预加重。这两个段在光域中结合它们的电光(EO)转换,以补偿微环驱动的带宽限制。
发送器的输入阶段采用连续时间线性均衡器(CTLE),为输入PCB通道损耗提供最高10 dB的均衡能力。然后,通过两级限幅放大器(LA)提供额外的 6 dB增益,输出至少达到 600mVpp。经过电平移位后,此输出进一步通过预驱动器提升,增加 3 dB增益至850 mVpp,从而满足驱动器最后阶段的输入要求。驱动器还集成了一个12位数模转换器(DAC),用于微调微环的谐振波长。
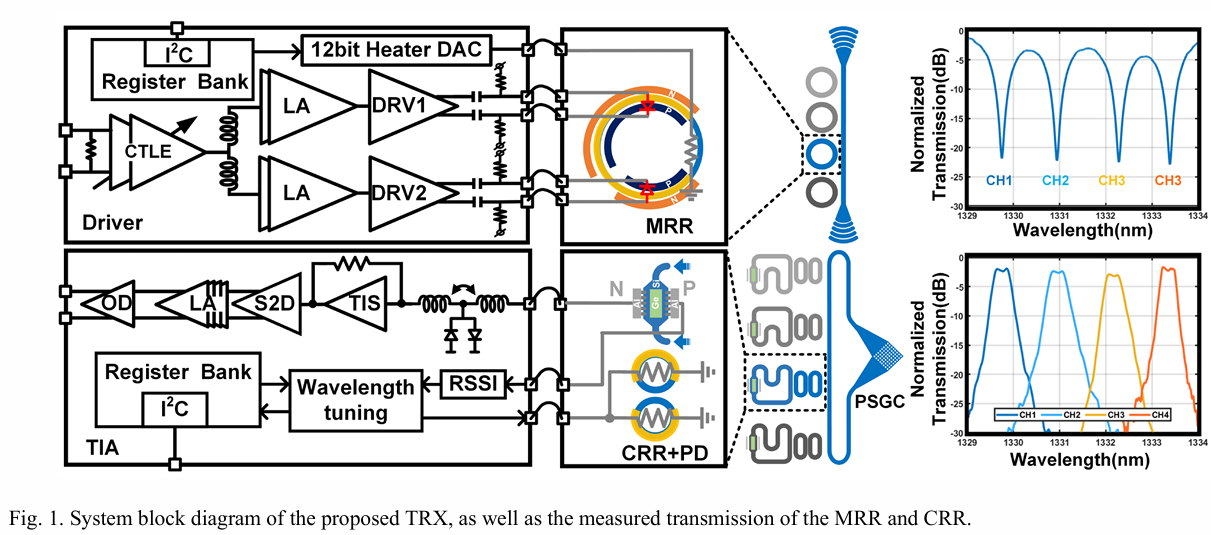
为了降低对入射光极化状态的敏感性并提高其强度,接收器(RX)使用极化分离光栅耦合器(PSGC)来接收横向电(TE)和横向磁(TM)光波。PSGC将入射光分成两个正交取向的波导,每个波导以TE模式导引光,以避免使用额外的极化旋转器。在双向光电探测器(PD)的两端,同时检测双向传播的光,提高了光检测的效率。为了减少WDM过滤中的信道串扰,采用了CRR设计作为滤波器。与单环滤波器相比,CRR设计提供了更宽更平的滤波响应,并具备更陡峭的边缘滚降,能够实现85 GHz的光学带宽。
由于双向PD的寄生电容增加,跨导阻抗级(TIS)采用了多种电感峰化技术来扩展带宽。来自PD的光电流最初在TIS和级联的单端转差分(S2D)转换器中被放大并转换为差分电压信号。限幅放大器(LA)用于进一步放大信号,确保其满足开漏驱动器的输入要求。50 Ω开漏驱动器采用源退化电容,提供可调峰化能力,以补偿板载通道中的损耗。
为了提高电流效率,CTLE和限幅放大器(LA)均采用基于反相器的Cherry-Hooper结构,这有效地使跨导(gm)加倍。此外,CTLE在PMOS和NMOS晶体管的源极中使用源退化电阻-电容(RC)网络以改善其均衡能力。在LA中使用电感峰化来高效分配高速信号到两个驱动器。
图2展示了所提议的双段驱动器的驱动阶段电路设计。左段DRV1采用级联电压模式(VM)拓扑,提供从0到VDDH(1.8V)的驱动电压。额外的晶体管M1和M2用于加速节点MP和MN的充电和放电速度,并防止晶体管击穿。在DRV1中,驱动拓扑被简化,只包括驱动晶体管,不含任何附加组件,确保驱动器的高效运行。预驱动器用Cherry-Hooper结构替换了级联反相器,以增强带宽和扇出能力。在每个Cherry-Hooper阶段的输出节点,一个紧凑的电感器用于带宽扩展。为了确保前一阶段可以跨高低电压域驱动预驱动器,在电平移位前采用两个专用电感器进行串峰化。
右段DRV2配备了分数UI延迟FFE(fractional UI delay FFE ),提供克服MRM带宽限制的均衡能力。在FFE路径中,结构类似于NAND和NOR门的控制逻辑被采用,其关键路径经过优化以减少寄生电容。级联的电流控制延迟元件用于实现分数单位时间间隔的延迟微调。在延迟输出节点施加主动峰化,以扩展带宽并保持信号完整性。
为了应对微环电-光(E/O)转换中的非线性问题,在输出节点部署了一对不对称电感器。通过对电感器的两个部分进行特别设计,调整电感值,使充电和放电路径中的串联电感不同,从而在下降沿时产生更大的峰化。此增强措施改善了微环光响应的下降沿带宽,并有效提高了消光比。输出节点电感器的另一个优点是,在充电或放电阶段,邻近pMOS/nMOS支路的寄生电容被电感所掩盖,从而提高了充放电速度。此外,这些电感还帮助将静电放电(ESD)和引脚的寄生效应分散离开驱动器的自身电容,有助于提高带宽。
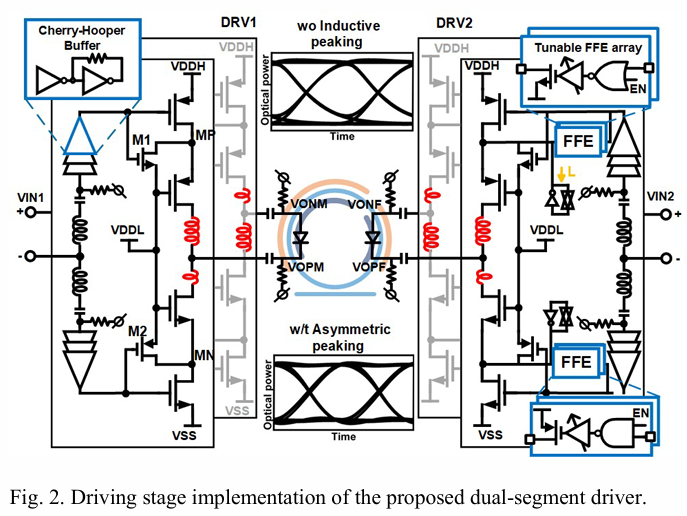
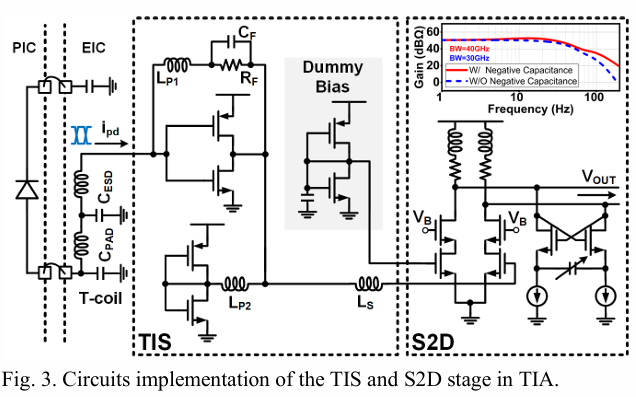
图3展示了所提议的TIA的前两个阶段的电路实现,即TIS和S2D阶段。为了扩展带宽,该实现采用了定制设计的T型线圈来重新分配输入节点的寄生电容。TIS采用基于反相器的拓扑结构,以加倍跨导(gm)。反馈电容(CF)用于实现巴特沃斯频率响应,并通过负载峰化(LP1)实现并联峰化。此外,还使用了短接反相器形式的电感LP2进行并联峰化。
S2D转换采用差分级联配置,一个输入端接地,并应用复刻偏置。该配置减少了与高负载条件相关的不利影响。此外,为提高转换性能,输出并联了一个负电容,以增加输出带宽。TIS和级联的S2D电路在负电容的帮助下实现了50 dBΩ的跨阻增益和40 GHz的带宽。这些结果是在供电电压为0.9V时以32 mW的功耗实现的。
所提议的驱动器和TIA是在28nm体硅CMOS工艺中制造的。图4显示了通过焊线连接光子芯片和评估板的驱动器和TIA的芯片显微照片。发送器(TX)和接收器(RX)电子集成电路(EIC)的总面积分别是0.7mm²和0.18mm²。

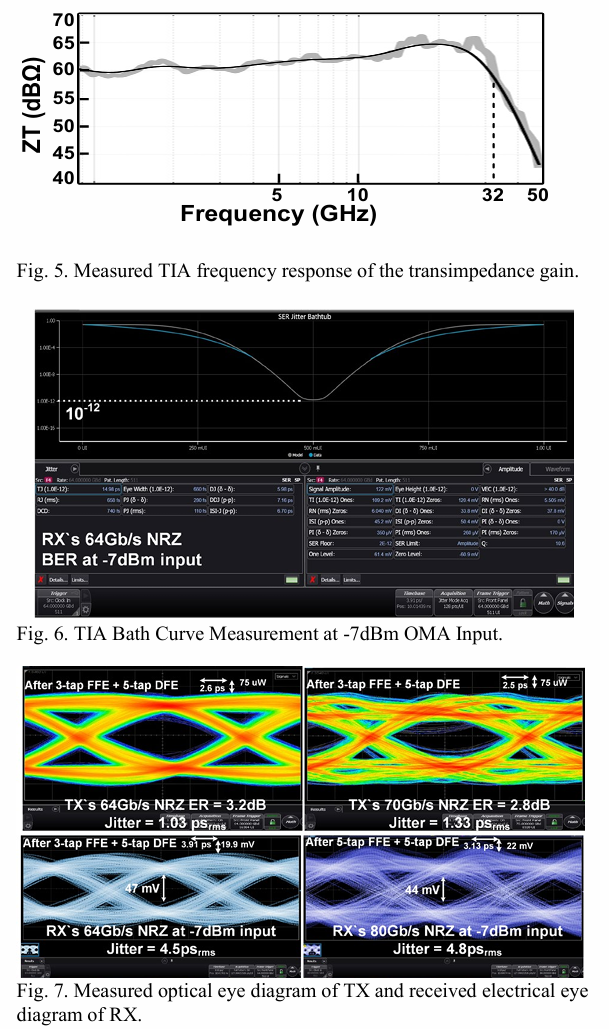
为了评估TX的传输性能,采用O波段激光源生成0dBm的激光,以避免自热效应并考虑耦合损耗,采用增益为15dB的PDFA来满足示波器输入要求。在图7中,TX的光眼图是在使用PRBS13模式编码的64 Gb/s、300mVpp输入信号下测量的。在不对称电感器的帮助下,测试期间获得的光眼图未显示显著的非线性效应。通过在示波器上应用3抽头FFE和5抽头DFE以模拟Serdes的均衡,64 Gb/s光眼图的消光比为3.2 dB,而RMS抖动为1.03 ps。最大传输速度可达70 Gb/s,此时消光比为2.9 dB,RMS抖动为1.3 ps。TX的功耗在运行64 Gb/s时为360mW,包括CTLE、LA和两个驱动阶段,因此TX的能量效率为5.62 pJ/bit。
在接收器(RX)方面,首先对TIA的电性能进行了表征。图5展示了TIA跨阻增益的频率响应,展示出60 dBΩ的跨阻增益。在片上CTLE的帮助下,TIA的带宽扩展到32 GHz。一个由商业调制器生成的O波段调制光信号被传输到接收器进行光性能分析。得益于PSGC的集成,测量过程中无需使用额外的偏振控制器。在PD输入端,当光学调制幅度(OMA)达到-7 dBm时,TIA的输出误码率(BER)恰好达到10^-12,如图6所示。我们认为OMA为-7 dBm是该光接收系统的灵敏度极限阈值。图7显示了在3抽头FFE和5抽头DFE下,64 Gb/s NRZ信号的单端接收电眼图,RMS抖动为4.5ps,眼高为47mV。图7还显示了在3抽头FFE和5抽头DFE下,80 Gb/s NRZ信号的均衡单端电眼图,RMS抖动为4.8ps,眼高为44mV。RX的功耗为98.1mW,能效为1.53 pJ/bit。表I总结了与其他最新技术的性能对比。所提议的发射接收器(TRX)在NRZ调制中实现了最高的传输速度。
在这项工作中,提出了一种基于28nm CMOS工艺的64Gb/s硅光子(SiPh)微环谐振器(MRR)收发器,其中包括共同设计的驱动器和TIA。所提议的双段MRR驱动器结合不对称电感器,有效克服了微环电-光(E/O)转换中的带宽限制和非线性问题,实现了64Gb/s的传输。发送器的光眼图达到了3.2 dB的消光比和1.03 ps的RMS抖动。最大传输速度可达70 Gb/s,消光比为2.8 dB,RMS抖动为1.33 ps。接收器在光功率输入为-7 dBm的情况下,实现了64 Gb/s时误码率(BER)低于10^-12的表现。在3抽头FFE和5抽头DFE的帮助下,实现了64 Gb/s接收,RMS抖动为4.5 ps,眼高为47 mV。
REF:
生成式人工智能(GAI)的普及使基于光子的计算因其满足更高能效性能(EEP)需求的潜力而备受关注。然而,以前的光学解决方案用于乘加(MAC)操作主要集中在模拟架构[1-7],其精度和数据转换有限,或者自由空间光学架构的可扩展性有限[8]。在此,我们报道了全球首个用于GAI训练的芯片上大规模数字光学计算系统(DOC)。DOC采用了一种新颖的基于晶圆的系统集成技术,具有多层低损耗光子互联扇出(PIFO)和利用台积电SoIC®的EIC/PIC叠加架构。它减少了数据移动和存储层级,从而改善了关键路径延迟和系统能效(EE)。与传统电子设计相比,DOC可以扩展到更大规模的相干网络,并以更低的能量每MAC操作在更高速下运行。在8位操作时,能量消耗低至<0.08皮焦/MAC,与最先进的GPU相比,在512 x 512MAC大规模操作中实现了超过20倍的EEP改进。由于相对较小的扇出能量,在更高精度下的EEP进一步提高。该架构完全有潜力在未来几代中实现持续的EEP扩展。
随着生成式人工智能(GAI)的使用增加,对更高计算能力和更低能耗的需求也在不断增长[1,2]。光学平台,特别是模拟架构,被提议作为一种具有竞争力的节能解决方案,包括Reck架构[3]、相干衍射光学[4-6]和LightMatter的推理Mars光子核心[7]。虽然光学模拟架构在过去十年中被深入研究,但由于相干性问题、器件损耗以及数模/模数转换设计,其仅在低精度应用和小规模上实际可行[8]。为了克服这一限制,MIT曾提出一种使用自由空间光学进行高能效复用技术以“被动传输和复制数据”的数字架构[8]。与电子不同,使用光学的一个显著优势是其能够直接进行低损耗的大规模扇出且与路径无关,从而减少了数据移动和延迟。此外,通过减少中间存储层级,内存层次结构得到简化,降低了整体内存访问的能耗[8]。这可能允许在大规模MAC操作中显著改善能效(EE)[8]。然而,自由空间光学难以扩展,其受限于衍射、光学元件的物理尺寸和对准要求。在所有光学自由空间架构中[4,5],各个光学元件的对准变得至关重要,而物理尺寸总会受到衍射极限的限制。因此,要实现高效率、高性能和大规模MAC操作的好处[8],需要一种高密度集成的低损耗光子扇出电路。类似于台积电InFO的电子扇出,设计了一种新型多层光子扇出DOC以实现所需收益。
DOC的集成流程遵循EPIC(电子-光子芯粒与集成电路工艺集成的平台技术[9])。EPIC-DOC首先在台积电SoIC®上进行EIC与PIC的叠加。然后移除PIC的背面硅。之后,多层PIFO结构如图1所示集成到PIC的背面。本文展示了一个用于512 x 512计算矩阵的超大规模、紧凑封装的光学扇出电路,具有-35 dB的光路损耗,允许能效改进和可扩展性。与最先进的GPU相比[10],在相同逻辑面积下,8位操作时能效性能提升超过20倍。此外,展示了计算单元尺寸的可调性,允许兼容各种应用。
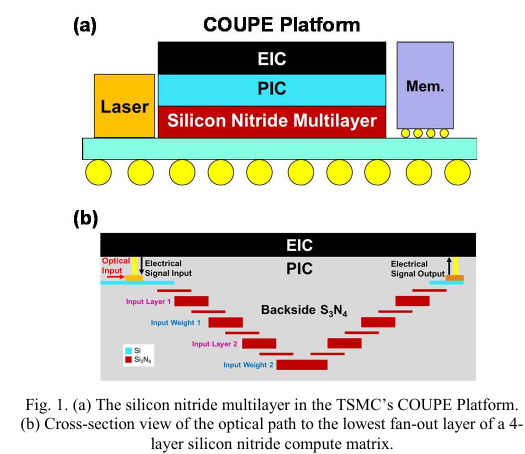
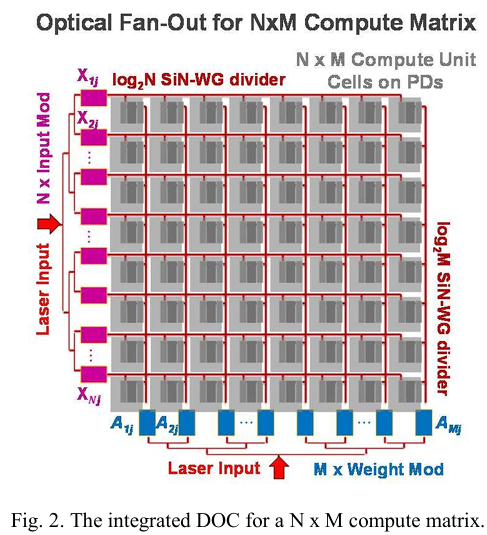
对于一个 N x M 数字光学计算系统(DOC),首先通过光子调制器将 N 个输入和 M 个权重电信号转换为光信号,这些调制器位于光子集成电路(PIC)上,如图 2 所示。然后,输入和权重信号在多层氮化硅中均匀分布,对于512 x 512 的计算矩阵,该分布分为两层。信号经过设计的1到512扇出电路传输到PIC上的光电探测器,以进行电信号转换。电信号被直接连接到电子集成电路(EIC),在此处通过位串行乘法器顺序进行MAC运算,并进行输出固定的累加[8]。
为了实现多路复用所需的大规模、低损耗、紧凑和路径长度控制的扇出特性,设计了两组封闭的1到512扇出电路。由于输入和权重信号的方向性,这两组可被区分为“水平”和“垂直”扇出。通过利用多层结构,封闭扇出的输出允许计算单元大小在不牺牲能效的情况下适用于各种应用,这与之前的树形扇出不同[11]。通过半对称扩展扇出实现了路径长度控制。
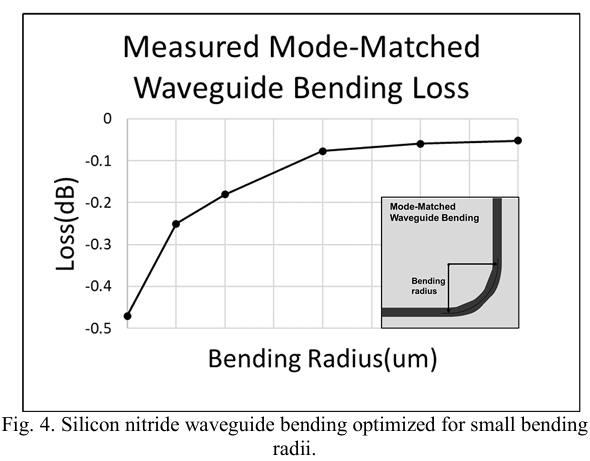
为了构建具有25微米 x 25微米计算单元大小的512 x 512计算矩阵,设计了紧凑的6平方微米的1到2分配器作为扇出的最基本结构单元,具有-3.25 dB的损耗,如图3所示。为了连接封闭扇出电路中的每个1到2分配器,设计了具有15微米至8微米半径的模式匹配波导弯曲,损耗分别为-0.05 dB/弯曲和-0.25 dB/弯曲,如图4所示。
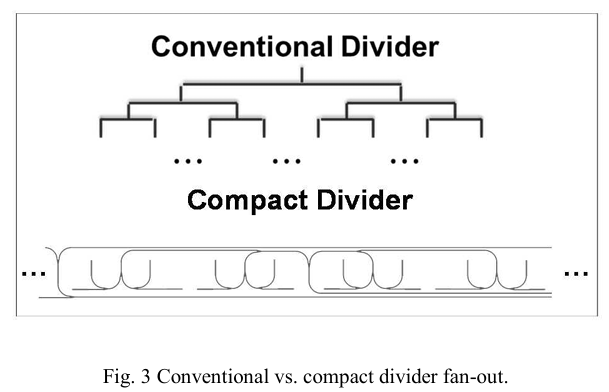
这是关键的,因为在螺旋图案封闭扇出中波导弯曲的高使用率成为限制计算单元大小的主要因素。
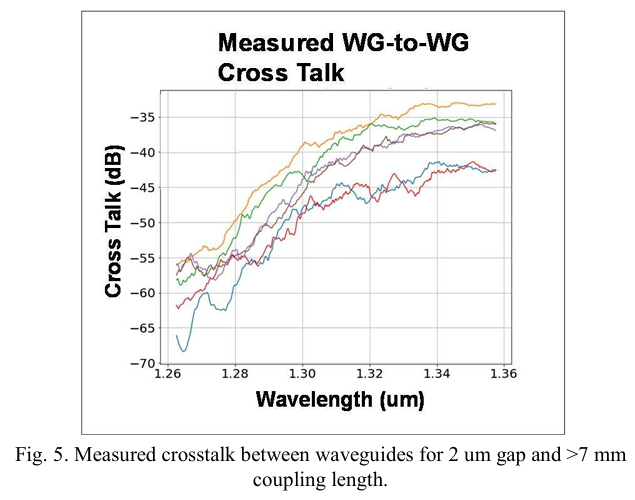
此外,波导宽度和间距被控制以防止串扰噪声,如图5所示。
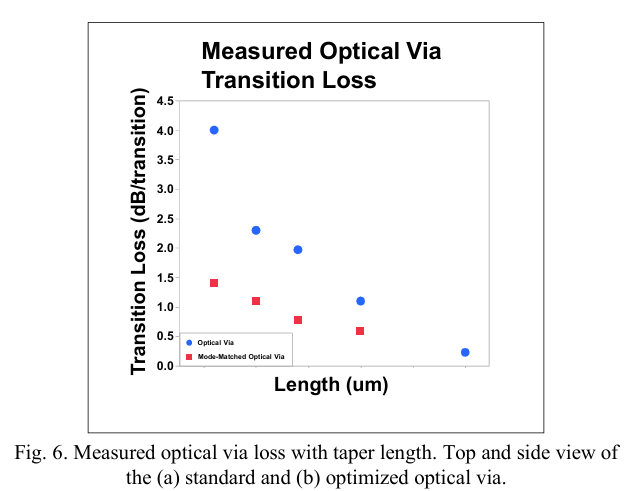
最后,设计了一个60微米²的光通孔,层间过渡损耗为-0.5 dB,以防止各层之间的显著功率差异,如图6所示。通过优化流程和设计,预计还可以实现层间过渡损耗小于-0.1 dB和超过3倍的占用空间减少。通过控制扇出电路中每个基本构建块的损耗和空间,占用实现了大规模1到N/M扇出的制造。
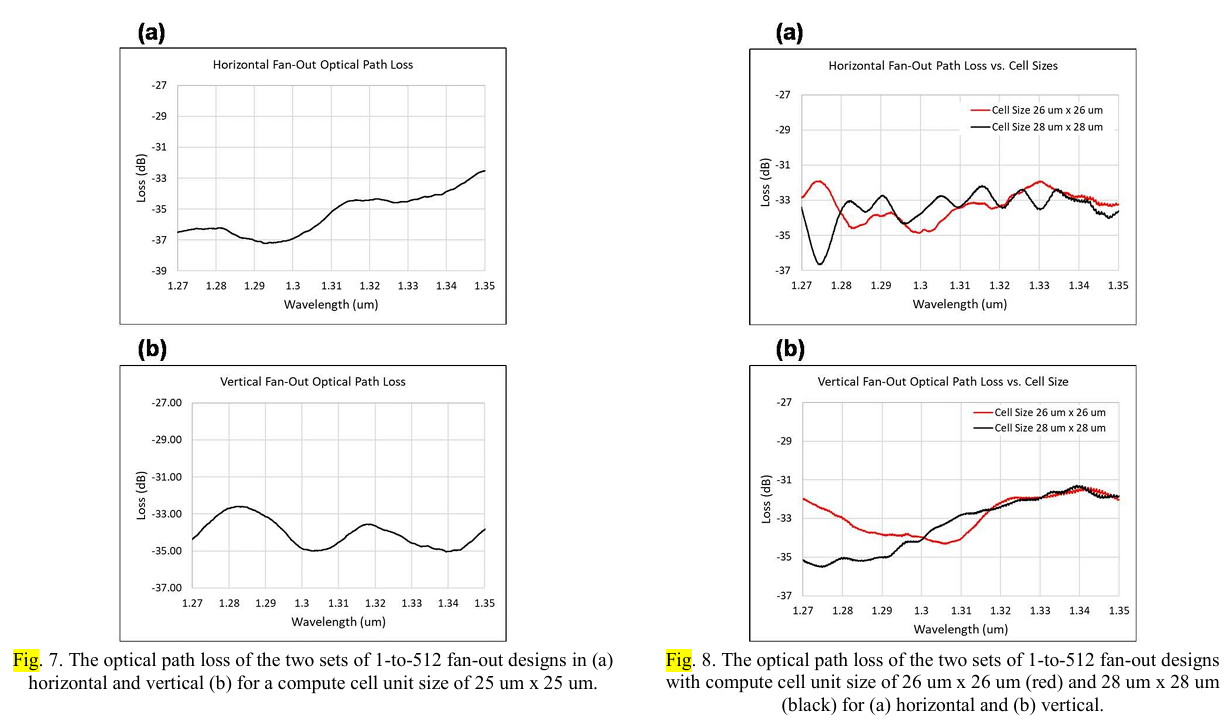
1到512扇出原型的测量总光路损耗约为-35 dB,测量专用的波导交叉损耗为-1.6 dB,由使用常规弯曲波导和当前工艺导致的损耗为-3.3 dB,如图7和图8所示。这允许可实现的最小可调计算单元大小为20微米 x 20微米,尽管具有更高的光损耗。
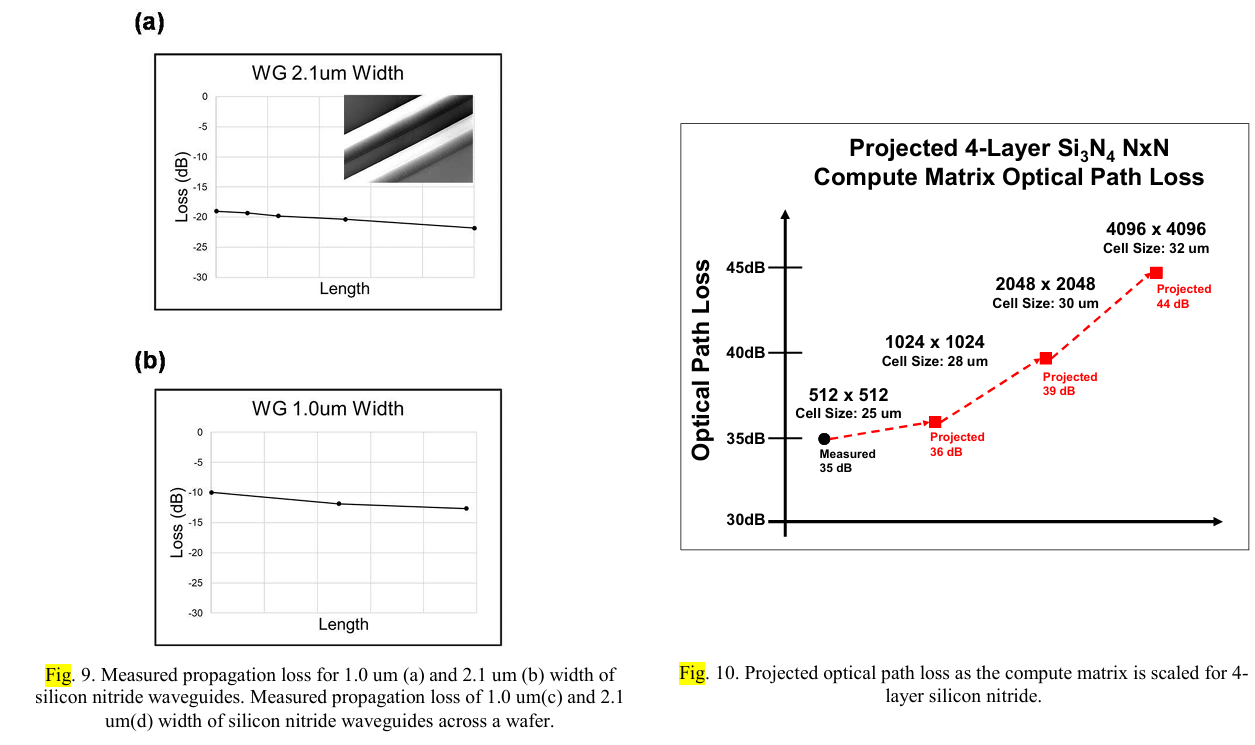
与前侧相比,EIC/PIC堆栈的背面为扩大设计的高效扇出网络提供了一个平台[12]。多层氮化硅有助于减少扇出的占用空间和损耗。硅氮化物波导在1微米和2.1微米宽度下的传播损耗分别为-0.1 dB/cm和-0.02 dB/cm,如图9所示。这一点至关重要,因为传播损耗与计算矩阵的大小和单元尺寸成正比。
由于扇出位于背面,PIC/EIC从中获益,简化了整体设计的复杂性。这允许在每一层实现专用功能,从而通过扩展扩大潜在的能效性能(EEP)改进。此外,通过利用COUPE平台在最小化PIC-EIC接口寄生损耗方面的优势,提高了EEP[13]。
在这种数字光学计算(DOC)架构中,总能效(EE)会随着精度的提高而显著改善。在低精度的MAC操作下,扇出能量占据了电力消耗的大部分。在高精度情况下,扇出能量将保持相对较小,与MAC操作中显著增加的功耗相比。因此,基于测得的损耗和经过优化工艺得出的估计改进,光路损耗可以如图10所示进行预测,假设激光器墙插效率为20%,调制器插入损耗为-2 dB,光纤到PIC连接损耗为-1 dB。基于这一损耗性能,可以实现预测的4096 x 4096 MAC操作。使用测量的工艺,DOC在8位情况下计算得出的EE约为0.15 pJ/MAC,相比当今技术实现了超过10倍的提升。通过优化工艺,预计在8位情况下可实现小于0.08 pJ/MAC的EE,能效性能获得超过20倍的提升。计算通过使用优化工艺后的光路损耗,假设调制器能耗为0.2 pJ/bit,每次SRAM访问能耗为0.1 pJ/bit [8],光电探测器的响应率为~1 A/W,以及每次MAC的EIC能耗为<0.025 pJ [8]。预计所提出的DOC在未来扩展到4096 x 4096 MAC操作以上时,由于系统集成和EIC/PIC的演变,其能效性能改进将显著。
本文展示了一种业界首创的集成芯片上数字光学计算(DOC)系统,该系统在台积电的COUPE上集成了PIC背面的多层光子互联扇出(PIFO)。与最先进的GPU相比,能效性能(EEP)提升超过20倍。DOC结构最大限度地减少了数据移动并降低了存储层级。该架构可以激发更多创新,并在未来的生成式人工智能(GAI)系统中具有持续提升能效性能的巨大潜力。