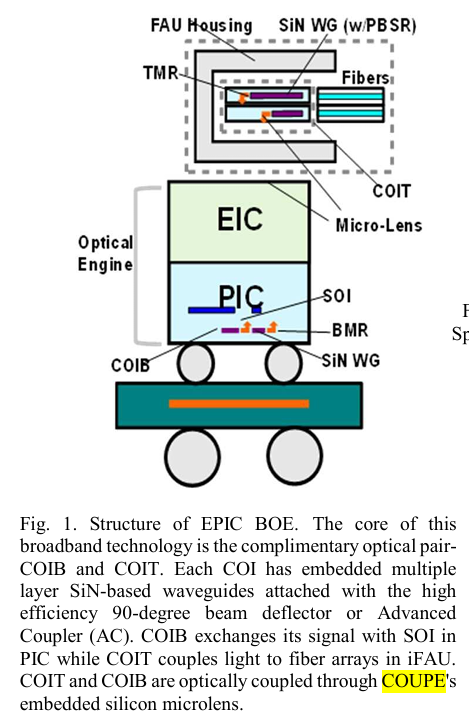
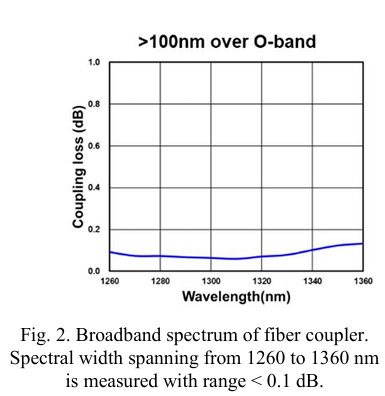
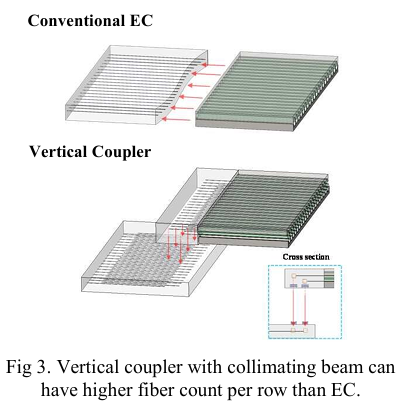
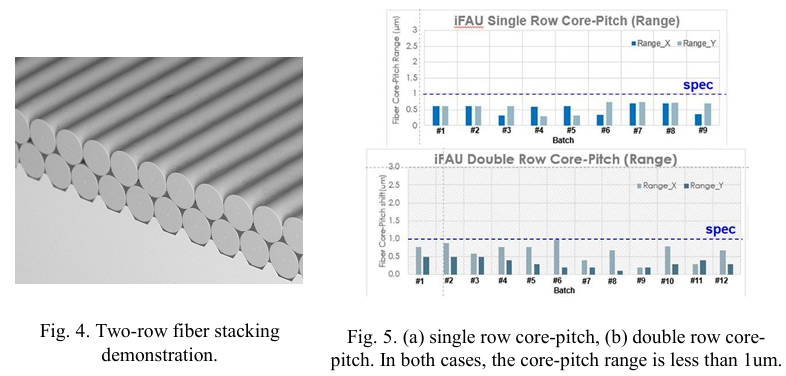
REF: High-bandwidth Chiplet Interconnects for Advanced Packaging Technologies in AI/ML Applications: Challenges and Solutions, TSMC,2024,11
摘要
使用2.5D和3D高级封装技术进行芯片组合集成的需求激增,这是由人工智能和机器学习(AI/ML)所需的计算性能指数级增长所推动的。本文回顾了这些高级封装技术,并强调了对高带宽芯片互联至关重要的设计考虑因素,这对于高效集成至关重要。我们解决了与带宽密度、能源效率、电迁移、电源完整性和信号完整性相关的挑战。为了避免功耗开销,设计芯片互联架构尽可能简单,采用带有前向时钟的并行数据总线。然而,要实现高产量的制造和稳健的性能仍然需要在设计和技术共优化方面做出重大努力。尽管存在这些挑战,半导体行业仍将持续增长和创新,这一发展受到坚实的芯片生态系统和新型3D-IC设计方法论所打开的可能性的推动。
背景介绍
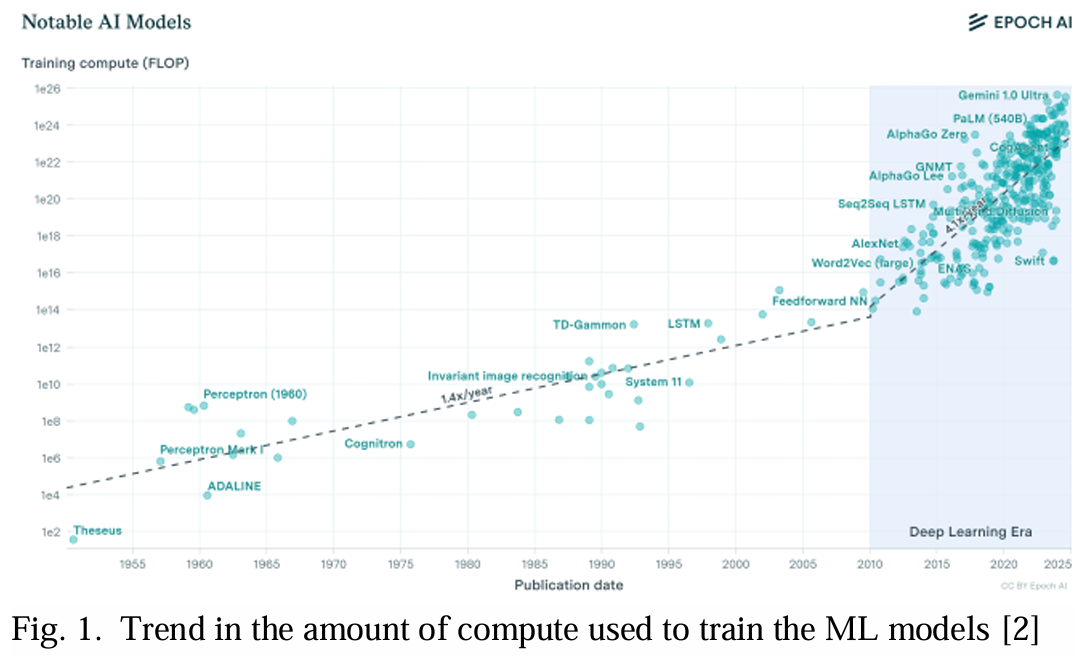
人工智能(AI)和机器学习(ML)技术的需求正在以前所未有的速度增长,远远超过摩尔定律预测的步伐。自2012年以来,AI训练所使用的计算量每年以4.1倍的速度指数级增长,超过了摩尔定律预测的每24个月翻一倍的速度[1][2],如图1所示。深度学习模型的参数数量的增加提高了它们的灵活性和潜在性能,推动了模型复杂性的迅猛增长。然而,这种扩张的速率正变得在经济(训练成本)、技术(计算机集群的大小)和环境(碳足迹)上不可持续[3][4]。为了部分满足不断增长的计算需求,必须关注算法效率和半导体规模的进步,旨在实现不仅更高的计算性能,还要实现能源效率高的计算性能[5][6]。AI工作负载需要大规模的并行矩阵乘法和累加运算,这些运算由并行计算核心的集群执行。这些工作负载需要大量的内存容量和高互联带宽。为了满足这种计算需求,一个典型的xPU/加速器芯片如今可能由许多计算、内存和IO芯片组组成[7][8][9],使用高级封装技术整合。每个芯片组设计在光刻步进机的光罩限制或视网膜尺寸内,为26 x 33 mm²。
使用芯片组提供了数个显著的好处。通过将大型单片芯片分解为更小的、容易管理产量的芯片组,设计师可以针对不同的工艺技术优化特定的功能,例如,使用最先进的工艺节点进行计算芯片的设计,并使用旧一代的工艺节点进行以模拟为中心的IO芯片和内存芯片的设计。这种模块化方法不仅简化了制造过程,而且还有助于快速的系统整合,特别是当使用标准化的芯片组接口时[10][11]。通过利用现成的芯片组,这种方法预计能显著降低制造成本和设计周期。
随着基于芯片组的封装系统在规模和复杂性上的增长,3D集成[12]和晶圆级系统集成[13][14][15]将提供更高的能源效率、卓越的性能和增强的成本效益[16]。然而,一些设计师在每一代产品上都熟悉的关键问题,继续对如今更大、更复杂的芯片组系统构成重大挑战。这些挑战包括热设计功率(TDP)、功率传输网络(PDN)损失、机械和热应力、网络拓扑和路由算法、互联吞吐量、能效、延迟、可制造性、冗余与修复能力、可测试性等等[16][17][18][19][20][21][22]。解决这些挑战对于确保先进半导体解决方案的性能和产量至关重要。
本文结构如下。第二部分概述了高级封装技术。第三部分讨论了大规模CPU/GPU系统中各种封装技术的芯片对芯片互联。第四部分深入探讨了芯片组互联设计的实际问题,如串行与并行接口、芯片组I/F信号、信道路由和信号完整性、焊点图规划、时钟方案、缺陷修复、ESD路线图和功率传输。第五部分引入了全面的3DIC设计流程。最后,第六部分探讨了未来的发展趋势。
高级封装技术和新功能
文献[23]对高级封装技术进行了出色的综述,将它们分类为2D、2.xD(包括2.1D、2.3D和2.5D)以及3D封装技术。根据这种分类,如果芯片组直接放置在封装基板上,就被认为是2D封装。当使用了如薄膜、桥或被动互连器等中间层时,则归入2.xD范畴。具体来说,如果互连器是带有通孔硅Via(TSVs)的有源芯片,则被归类为3D封装。虽然这种分类直观,但同时也有些任意性。随着封装技术的不断发展,这些类别之间的界限可能变得越来越模糊。为了简化讨论,大多数中间的2.xD技术通常都被归类到2.5D范畴。同时,2D、2.5D和3D集成技术也可能在高级封装解决方案中共存,使用3D-IC一词广义地指代这些解决方案。不论这些区分,主要焦点将依然是利用这些技术在半导体设备中实现更优的性能、效率和功能。
图2展示了台积电正在发展的3DFabric™技术组合。作为广泛采用的高级封装技术的一个例子,3D Fabric是一套全面的集成技术,将多个芯片与更紧密的物理邻近性和更高的互联密度结合在一起,所有这些都来自单一供应商。这种集成实现了更小的外形尺寸、更好的电气性能,以及大大增强了数据带宽。更重要的是,这些技术允许系统设计师将原来的单片SoC划分为芯片组,并在一个封装中构建更强大的系统[5]。不同的3D Fabric封装选项保持一致性。这种连贯性是有益的,因为3D-IC的复杂性要求设计规则在大规模制造之前要兼容并且持续进行验证。
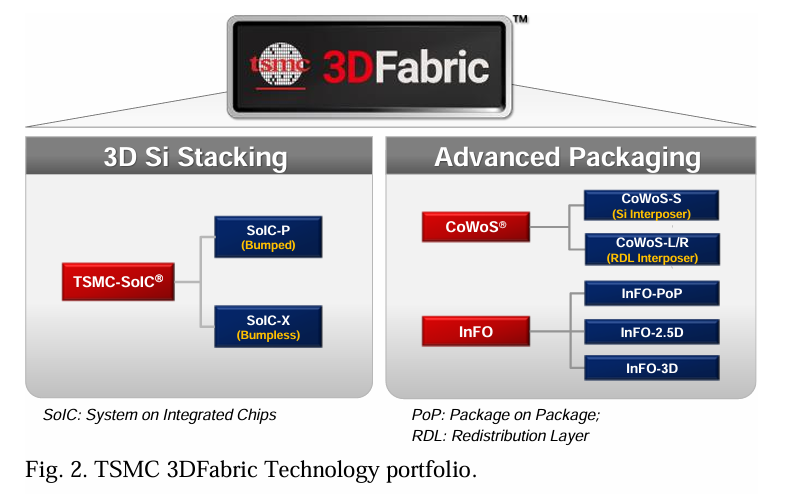
两种不同的封装平台来自于不同的应用。第一种是芯片-晶圆-基板 (CoWoS™, Chip-on-Wafer On-Substrate) 平台,自2012年以来一直在生产,主要用于高性能计算。它有三个子系列。CoWoS-S 配备了一个硅中介层,允许非常密集的金属线(W/S = 0.4/0.4µm)。CoWoS-R 则[26][27]在有机中介层中嵌入了重新布线层(RDL),其布线密度较低(W/S = 2/2µm)。CoWoS-L [28] 结合了-R和-S的最佳优点:局部硅互连(LSI)用于高布线密度,而有机基板中的RDL则具有更好的电气性能。-S 或 -L 选项还可以在硅中介层或桥中嵌入深沟槽去耦电容器(DTC)[29],以增强电源传输。
第二个是集成扇出(InFOTM)平台[30]。InFO自2016年起开始批量生产,最初是受到经济高效的移动应用的驱动。封装在封装上的InFO(InFO-PoP)[30]是第一个3D风扇出晶圆级封装技术,采用细间距铜RDL将SoC与内存封装集成在一起。因其成本、外形尺寸和更好的信号完整性,InFO技术已经演变出许多变种,显著扩展以允许集成更多功能芯片,用于HPC应用[15]。InFO平台还具有先进选项,如局部硅桥用于更精细的金属布线,以及嵌入去耦电容器来提供更优的功率供应。InFO是一种芯片优先的方法,将芯片正面朝下放置在临时载体上,并围绕它们构建RDL。另一方面,CoWoS则是一种芯片最后的方法,首先制造出芯片,然后将其放置在硅互连器上,随后将其依附到基板上。这种制造步骤上的区别影响到集成密度和热管理。具体来说,在芯片优先的方法中,硅将在后续周期中经历热循环。而且后期步骤缺陷的成本也远高于芯片最后的方法。
3D堆栈已在内存产品中广泛使用,包括高带宽内存(HBM)[31]和NAND闪存[32],并且随着芯片制造商对计算密度和数据带宽的需求增加而被采用[33][34]。集成芯片系统(SoICTM)适用于这种3D芯片堆叠[35]。它包括带有微凸点(间距为18-25μm)的SoIC-P和带有先进键合(间距为3-9μm或更低)的SoIC-X[36][37][38]。
SoIC实现了多芯片在垂直堆叠配置中的无缝集成,为系统设计和性能优化解锁了新的可能性。此外,SoIC可以与CoWoS或InFO结合,形成更强大、更灵活的计算系统。
芯片制造商和外包半导体组装和测试(OSAT)供应商提供了一系列先进封装技术[23][38][39],每种都有自身的优缺点和在信号完整性、互连密度、可制造性和热管理方面的权衡。例如,英特尔的嵌入式多芯片互连桥(EMIB)[39]和AMD的突出风扇出桥(EFB)[40]都是具有无TSVs的高密度被动桥连接配有额外的RDL以增强功率完整性的特点。选择特定封装技术取决于特定应用需求和所需的性能特性,尤其是在高性能计算领域,其中速度和能源效率至关重要。这也在互连设计上提出了限制和挑战,将在随后的部分中进行探讨。
芯片到芯片互连应用
图3显示了芯片封装从焊接点间距缩小视角下的演变过程,从传统的2D标准封装类型或多芯片模块(MCM)110-130µm焊接点间距,到2.5D先进封装类型(例如,CoWoS/InFO)-40µm间距,再到3D芯片对晶圆或晶圆对晶圆类型(例如,SoIC)<9µm间距[11]。随着焊接点间距的减小,在给定面积内的芯片到芯片信号数量成平方增长,从而增加带宽密度。电路架构的选择在间距缩小的背景下极大受到如可达距离、带宽、能效和延迟等因素的影响[41]。例如,在MCM封装中通常使用高达~56/112Gbps的高速串行器/解串器(SerDes)[42]以最大化每个引脚的数据速率。相比之下,2.5D中介层通常由于其卓越的能效和面积效率而使用高速并行数据总线[41]。同时,先进的3D堆叠技术则从较简单、低速的数据总线中获益最多,这些总线使用最少的CMOS缓冲器和触发器,不需要均衡器或校准电路,从而实现最佳的面积带宽密度和能效[11]。
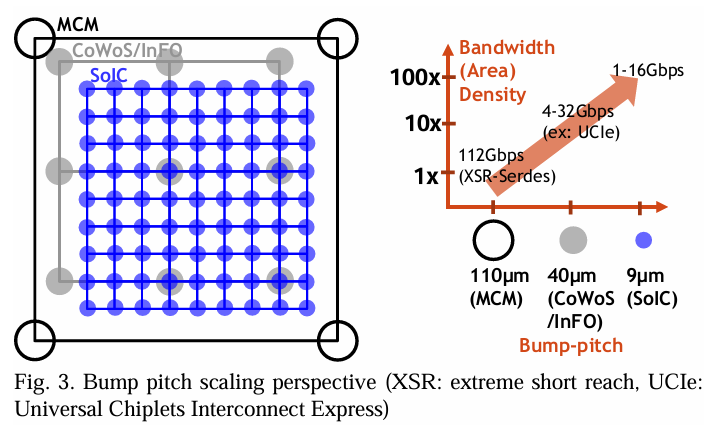
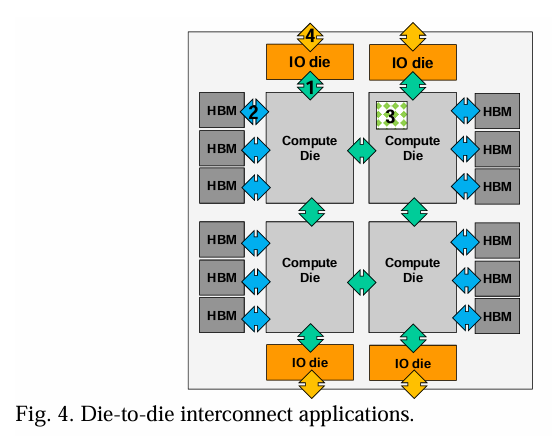
图4展示了一个通过多个小芯片来扩展计算性能和用于AI应用的扩展的示例。小芯片之间的芯片到芯片互连可以分为四类:1) 计算到计算 & 计算到IO:基于CoWoS/InFO技术的UCIeTM PHY,2) 计算到内存:基于CoWoS技术的HBMTM PHY,3) 计算到SRAM:基于SoIC技术的3D堆叠,4) IO小芯片到外部IO:基于标准封装技术的XSR-Serdes。
当前最广泛使用的AI加速器采用这种拓扑结构以最大化计算性能和内存访问带宽[43][44]。诸如晶圆级系统等竞争性技术[13][14]为未来计算系统的可能候选提供了一些初步的见解。这些系统的互连和网络拓扑将需要相应地演变以满足系统性能需求。
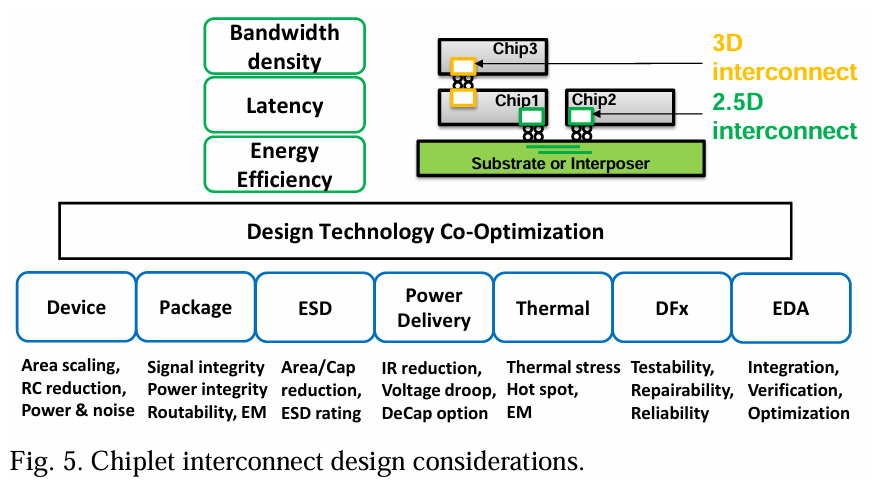
小芯片互连设计注意事项
小芯片互连设计目标和设计技术协同优化 (DTCO)
将以前的单片SoC拆分为多个通过高带宽小芯片互连连接的小芯片,可以实现更灵活的系统分区,并利用现成的小芯片提高良率和缩短周转时间。小芯片接口的标准化是一个重要的里程碑,比如通用小芯片互连表达(UCIeTM)[11]就是一个例子。在此之前,业界还采用了几种小芯片接口,以满足小芯片系统的需求,强调高带宽密度、低延迟和高能效。值得注意的例子包括高级互连总线(AIB, Advanced Interconnect Bus)[45],一束线(BoW,Bunch of Wires)[46],开放高带宽接口(OpenHBI,Open High Bandwidth Interface)[47],以及Lipincon(台积电专有)[48]。 图5提供了有关以满足2.5D或3D小芯片基系统中高速互连的性能和制造目标的多方面设计和技术协同优化(DTCO)努力的全面概述[49]。DTCO的范围涵盖了广泛的考量,包括但不限于:
- 设备级优化:重点是提升晶体管带宽和噪声性能以改善IO能效。
- 封装优化:通过平衡线路间距、层厚和通孔封装等关键参数来优化中介层上的封装设计规则,对于功率完整性(PI)、信号完整性(SI)、可路线性和可制造性至关重要。
- ESD:在小芯片系统中,ESD保护和ESD建模面临新的挑战[50]。必须仔细评估先进封装的ESD等级,以确保ESD面积和电容的开销不会影响IO能效。
- 电源分配网络(PDN):涉及管理由电源提供引发的电子迁移(EM)和IR压降、电压波动和串扰。
- 热管理:主要挑战包括准确模拟热点,并减轻热循环导致的问题,如时间漂移、机械应力和电子迁移。这涉及在设计阶段[51]或运行时[52]实施解决方案,以将设备维持在安全温度范围内,从而保持性能、可靠性和寿命。
- 为可测试性、可修复性和可靠性而设计:确保这些方面有助于有效的短期测试和长期寿命,这对产品的成功至关重要。
- 设计签核流程:高效的、AI辅助的EDA工具和流程对于生产力和优化越来越重要[53]。
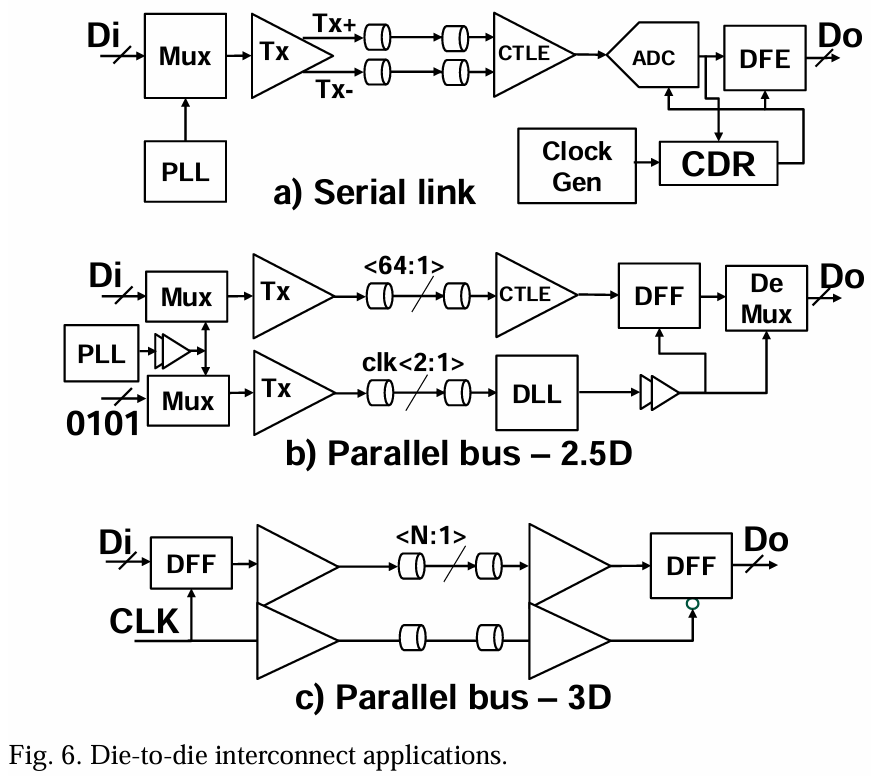
串行与并行数据总线
在标准封装(MCM或2D)中,信号焊接点和金属线的间距较大。为了最大化每个引脚的数据带宽密度,人们被迫使用串行链路(例如,PCIe 32/64Gbps,CEI-112/224Gbps)与差分信号,如图6-a所示。
先进封装技术(2.5D)允许在较小的数据速率下,通过单位几何形状的更多并行单端信号来最大化接口带宽密度或面积带宽密度(例如,UCIe x64在4-32Gbps范围内)[11]。并行接口(图6-b)在几个方面表现突出。首先,并行接口伴随着一个用于抖动和偏斜跟踪的前向时钟,消除了每通道时钟数据恢复(CDR)机制的需求,从而简化系统并降低延迟。其次,并行接口的较低数据速率运作意味着系统在信道损失、抖动和串扰方面受影响较小。所需的信道均衡(EQ)更少,消除了电路负担,实现了更高的带宽密度和更好的能量效率。
对于3D堆叠,信号密度非常高(间距P ≤ 9µm),3D互连电路面积需要小于焊接面积(P²)以最大化互连效率(定义为带宽密度*能量效率)。在这种情况下,并行数据总线的速度被限制在5Gbps,以简化定时[11]。不需要校准和适应性调整,有效地降低了功耗、延迟和面积开销。UCIe-3DTM就体现了这种精神(图6-c)。
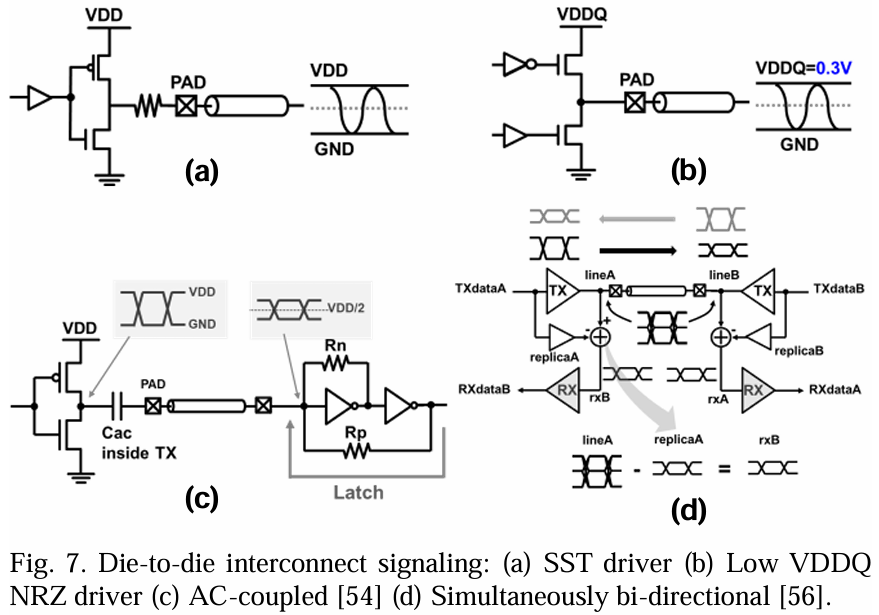
芯片到芯片互连信号传输
先进的封装技术能够实现芯片更近的距离和减少互连负载,从而提高信号完整性、数据速率和电源效率。非归零(NRZ)和四级脉冲幅度调制(PAM4)信号有可能成为不同运行速度的候选方案。如图7所示,核心供电(例如,Vdd=0.75V)的SST(源端串阻终端)驱动器常用于优化眼图裕度和阻抗匹配。NFET-NFET驱动器已被采用以在低VDDQ(例如,<0.3伏)下运行以减少功耗[48]。然而,这种额外的电源域可能会因路由资源稀缺而不理想。当在PAM4奈奎斯特频率下的插入损耗上有显著优势时,PAM4是有益的,但它在中间电平消耗直流电流,使其对低损耗先进封装通道不太适用。另一种低功耗驱动器选择是交流耦合[54],通过减少驱动器强度和信号幅度来降低功耗。同时双向(SBD)数据传输也可以在给定的界面上将数据带宽加倍[55][56]。
信道可布线性与完整性分析
对于高布线密度(例如,最小间距0.4µm),适当的信号间隔离是必要的,以实现足够的串扰隔离和更好的信号完整性。如图8所示,代工厂内的信道优化涉及许多指标,如介电厚度、金属间距、金属厚度、可用金属层、通孔封装、堆叠规则等。针对每种先进技术的中介层进行设计和技术协同优化,经常推动设计规则以在可制造性、可布线性和信号完整性(SI,包括插入损耗和串扰,如图所示的曲线)之间保持良好的权衡。
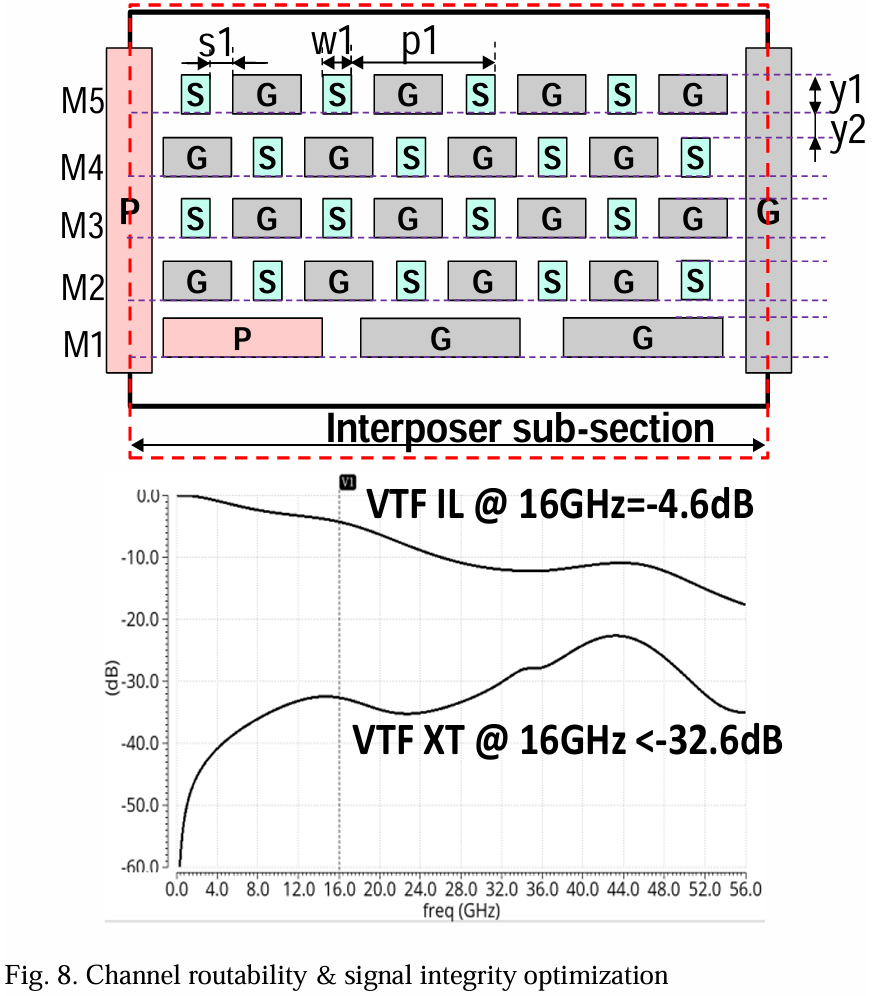
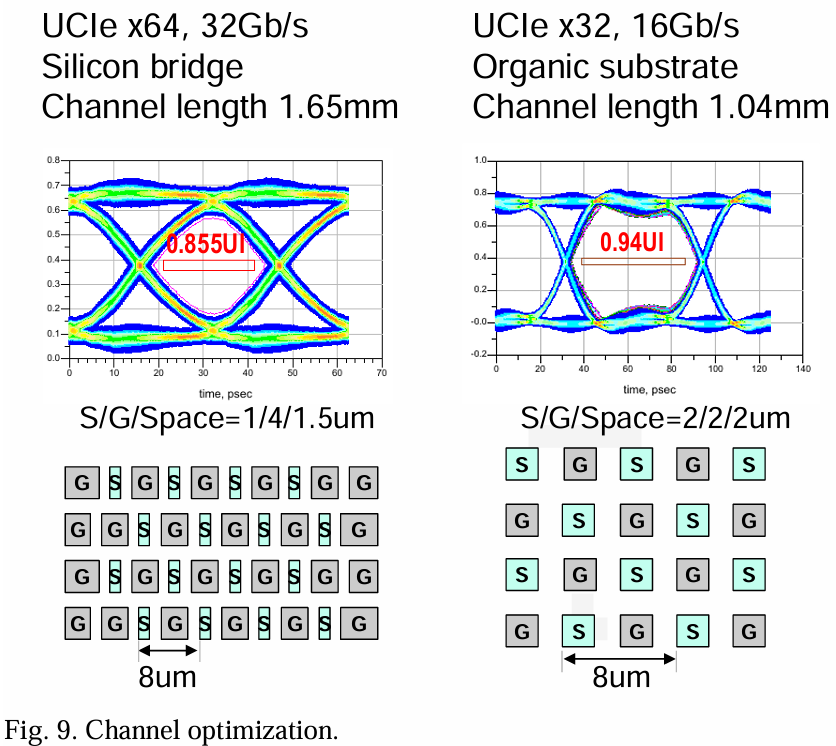
图9展示了两种不同代表性封装和不同隔离风格的UCIe芯片间布线设计示例。InFO(硅桥)有局部硅互连,金属厚度为2µm,而InFO(有机基板)则有再分配层(RDL),金属厚度为2.3µm。两者都有4层信号布线金属和1层电源网格。前者具有更紧的金属宽度/间距细分。两种情况下信号间距为8µm,前者可以允许更宽的金属隔离和略大的信号间间隔。因此,前者能够在32Gbps速度下运行x64 UCIe标准,而由于更严重的串扰,后者仅能在x32数据通道上达到16Gbps。
2.5D和3D形态结构
互连模块的某种形态结构,包括模块几何形状、信号顺序、焊接点间距、多模块堆叠等,对于确保不同小芯片供应商之间的整合兼容性至关重要。尽管这种标准化为小芯片生态系统带来了刚性,但简化了IP开发——只需支持有限的IP变体。然而,需要注意的是,某种给定的形态结构在面积、功耗和成本方面可能并不总是最佳的。以UCIe为例:最初发布的x64(64 Tx + 64 Rx)形态结构,随后提供了适用于低成本高级封装且再分配层(RDL)数量较少的x32(32 Tx + 32 Rx)形态结构。最初的10列模块针对的是45µm的焊接点间距。为进一步提高面积效率,联盟后来引入了适用于较小焊接点间距(<38µm)的16列模块和用于较大焊接点间距(>50µm)的8列模块[11]。这些连续的调整在满足不同应用的不同需求之间,平衡了成本和性能。
当前的UCIe协议支持对称的双向数据发送和接收,这对于同质xPU小芯片之间的数据通信是典型的。相比之下,芯片生态系统中的关键组件——高带宽内存(HBM)接口,表现出不对称的内存访问(读/写)带宽。为了在不引发严重信号完整性问题的情况下扩展接口带宽,未来的HBM4将双向数据IO的数量从1024增加到2048[31]。扩展HBM以增加带宽通常受限于布线拥堵和信号完整性问题。通过将基底逻辑转移到先进的制程节点,可以缩短互连路径,从而改善信号完整性和速度。或者,使用类似UCIe的SerDes IO作为HBM接口可以通过更少的信号路径达到更高的通道速率,同时改善信号完整性并维持相同的带宽密度。
另一个显著的小芯片应用是数据转换器和逻辑处理器之间的接口。JESD204D是最新的高速度串行接口标准,定义了数据转换器的高速串行接口[57]。它包括ADC(模拟到数字转换器)的数据接收接口和DAC(数字到模拟转换器)的数据发送接口。这些标准适用于PCB级或多芯片模块小芯片集成。然而,尚未为高级封装中的数据转换器建立小芯片标准。
虽然可以想象开发一个可满足三种不同系统的通用小芯片标准——同质双向核心到核心接口、非对称内存访问接口和单向数据转换器接口——但每个系统仍需不同的形态结构以实现最佳性能和效率。
3D堆叠是实现更高能效的自然选择,主要因为短的芯片内布线显著减少了芯片间数据移动所需的能量。3D互连集群对于形成内在计时鲁棒性的硬IP模块至关重要,如图6-c所示。这种内建的计时鲁棒性允许模块化计时签核,确保3D堆叠中每个芯片的计时验证可以独立且自成一体地进行。
在图10中,我们提出了一种采用AB|BA模式的3D集群结构,其中模式A代表发射器(TX),模式B代表接收器(RX),或反之亦然。方形A/B模式可以根据系统需求配置为各种尺寸,例如4x4、8x8或20x20。RX和TX时钟位于各自区域中心,为每个I/O引脚和整个芯片提供最佳平衡。电源和接地在IP集群内对称分布。这种配置具有设计单一IP模块的优势,该模块具有特定的多晶栅极取向,可以适应任何小芯片取向,前提是假设在小芯片级别可以轻松实现逻辑电平引脚重新映射。
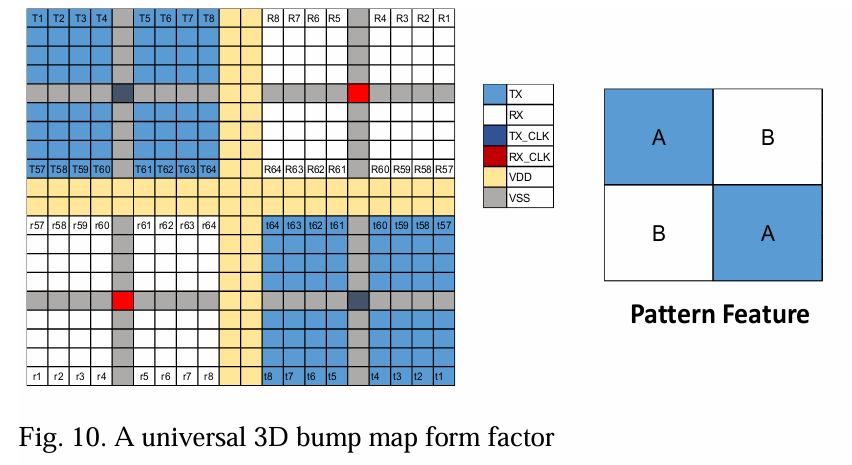
这种结构促进了SoC级别的轻松扩展,使得通过SoC上的IP实例化,实现不同的小芯片到小芯片堆叠场景。我们提出四种面对背(F2B)和面对面(F2F)连接选项用于SoC级别的扩展:在X方向上镜像或阶梯式,在Y方向上镜像或阶梯式。
图11展示了两个集成示例: 1. 情况1:‘X-镜像 / Y-镜像 / 芯片到芯片之间镜像’ - 此配置支持所有F2F和F2B芯片到芯片堆叠场景。 2. 情况2:‘X-阶梯式 / Y-阶梯式 / 不在D2D之间镜像’ - 此设置在芯片之间具有相同的焊接图。它支持F2F堆叠,但F2B堆叠需要90度旋转。
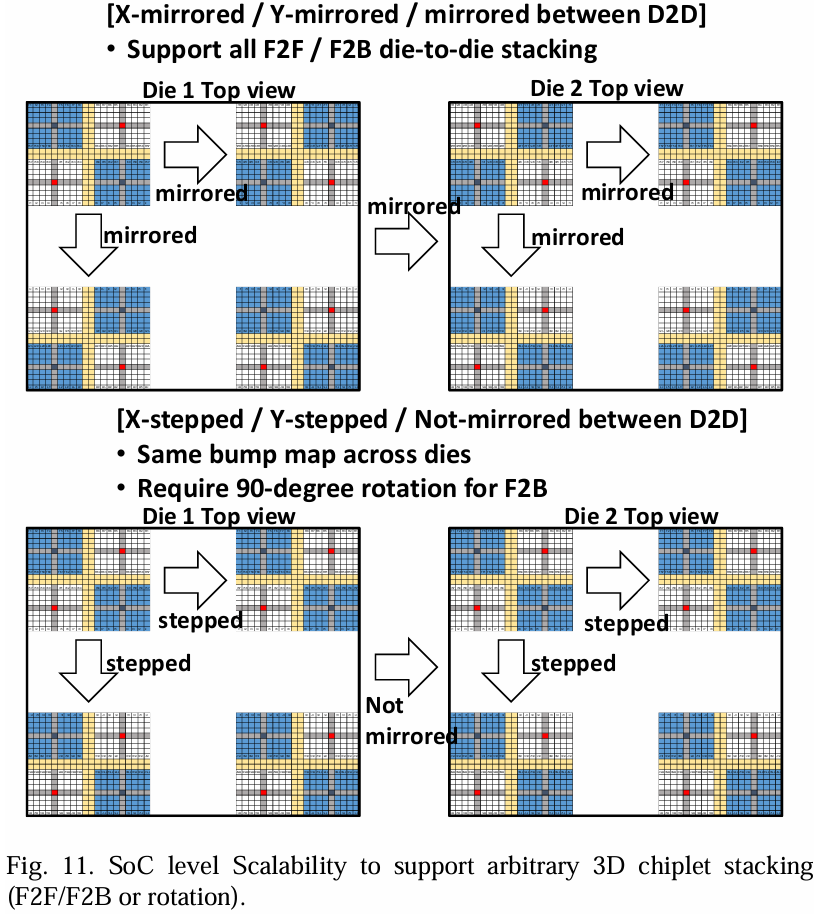
这些灵活的集成方法确保IP集群可以在各种小芯片堆叠配置中有效利用,促进SoC设计中的可扩展性和效率。
通道去偏和时钟对齐
在并行数据总线和前向时钟拓扑的基础上,需要对数据通道和时钟通道进行对齐,以最小化通道间的偏斜。通道间的匹配通过发射器(Tx)和接收器(Rx)在焊接点布局规划中的反镜像物理对称性来实现。然而,当需要连接两个不同的形态结构时,物理对称性将失效。例如,8列UCIe与10列UCIe的接口,通道本质上是不匹配的。此外,随机的电路不匹配和芯片上/封装上的线不匹配会增加额外的偏斜。需要在叶时钟树的每个通道基础上分配足够的偏斜调整范围,以实现发射器和/或接收器处每个通道的偏斜校准。在接收器中,数据采样时钟进一步调整到Rx数据眼的中央,以获得最佳的左眼和右眼裕度。
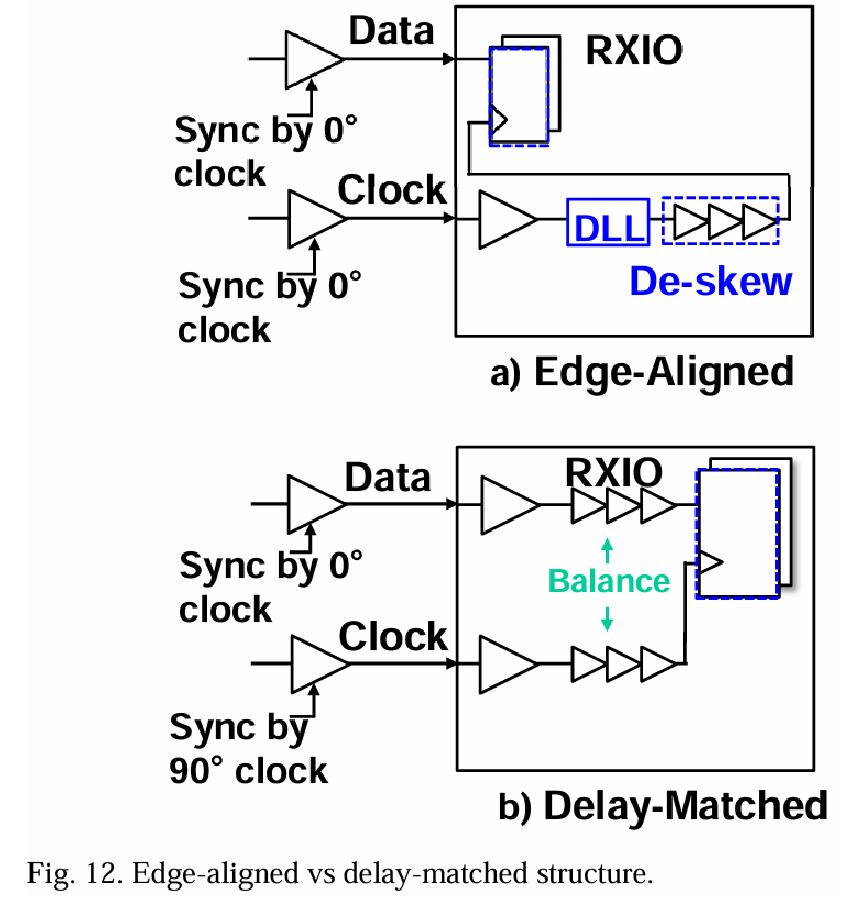
图12中展示了两种前向时钟生成的时钟拓扑。边缘对齐拓扑(图12-a)具有数据转换和时钟转换的对齐;接收器中采用本地DLL生成相位偏移90度的时钟来采样Rx数据眼。边缘对齐拓扑旨在减少电路并提高能效,但对温度或电压漂移引起的不匹配敏感,因此仅适用于较低数据速率(例如低于20Gbps)的应用。延迟匹配拓扑(图12-b)在发射端生成I/Q时钟(使用DLL或PLL和相位插补器),I时钟进入数据路径,而Q时钟被前向到接收器。时钟和数据路径在结构上匹配,以保持良好的抖动跟踪和延迟跟踪。
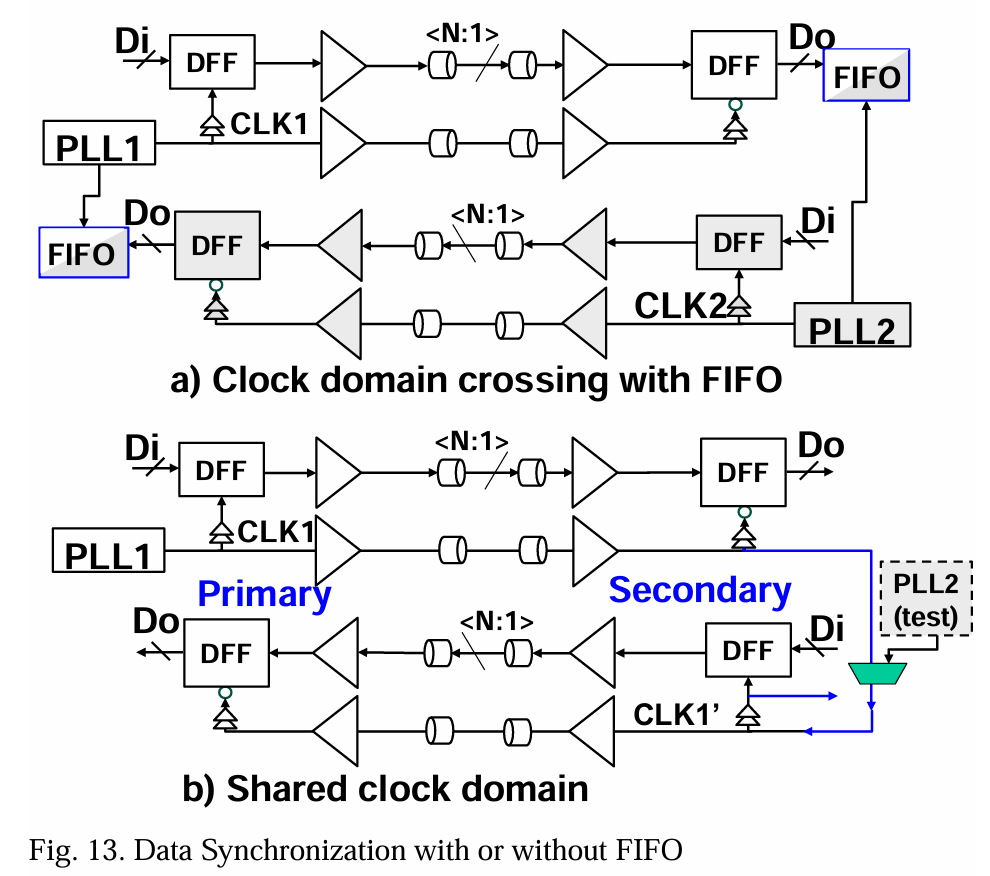
在大多数情况下,发射芯片和接收芯片使用独立的PLL和时钟域。为实现两个PLL域之间稳健的时钟域交越,通常需要先进先出(FIFO)数据缓冲器,这会带来额外的功耗和延迟(图13-a)。对于像核心到内存连接这样的接口,可以在两个堆叠的芯片之间强制使用单一时钟域。在图13-b中,我们提出了一种可实现两个芯片之间单一时钟域的替代方案,其中PLL1的主时钟从主芯片前向到辅助芯片并返回主芯片。这使得3D芯片间接口可以在无需FIFO的情况下发送/接收数据。第一捕获触发器(DFF)边界处的时间裕度可以保持与图13-a相同。在主芯片中,RxDFF后的数据重捕获时间裕度略受两个前向时钟路径延迟影响,这是可控的。
冗余与可修复性
冗余与可修复性是微处理器领域广泛研究的主题。[58]确定了三种不同的冗余策略:
组件级冗余:这包括拥有多个并行的功能单元,如多个CPU核心。在这种安排中,一个或多个核心的故障不会影响系统的整体功能。
阵列冗余:这种类型的冗余增加备用结构,可以替换有缺陷的结构。阵列冗余的一个常见应用是在缓存存储器中,备用元素替换故障元素以保持性能。
动态队列冗余:这种方法涉及动态标记和禁用有缺陷的元素,从而防止其使用并维护系统的完整性。
利用这些冗余策略,处理器可以实现更高的可靠性和更容易的可修复性,确保即使在故障出现时也能保持稳健的性能。
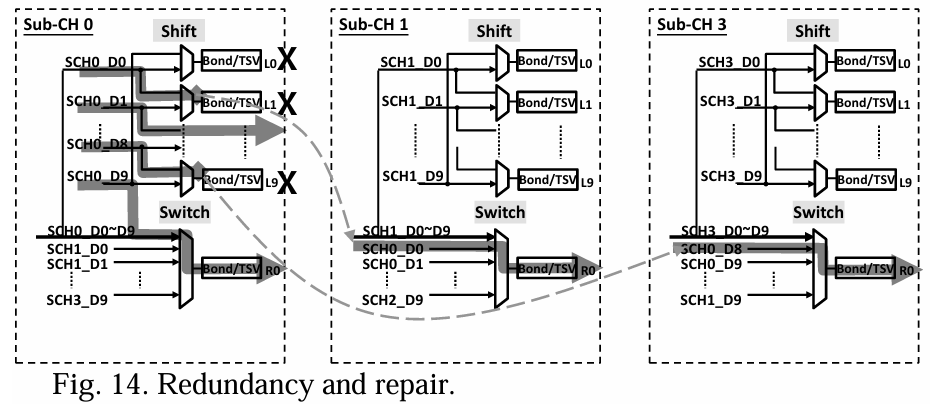
由于芯片之间是通过密集的微凸点或先进的键合连接的,检测和修复缺陷对于保证封装后的芯片良率是必不可少的。上述三种策略都可以适用于小芯片互连。图14展示了一个示例,其中使用“移位和切换修复”概念[21]来修复三个失效通道,仅需一个过十的硬件冗余。基于二项分布的概率计算[58]表明,这种30+3联修方法比三个独立的10+1组实现了1000倍的更低故障率。
对于如汽车业等AI/ML正在成型的关键任务应用,处理器故障的风险很高,因此当处理器能够响应不断变化的应用行为以维持其寿命可靠性目标时,动态可靠性管理技术是有益的[59]。在修复能力和信号完整性之间取得平衡需要进行战略性权衡。例如,分离电源和地凸点有助于防止永久短路故障[22]。然而,这种方法可能导致增加的面积开销或信号完整性的妥协。
静电放电迁移
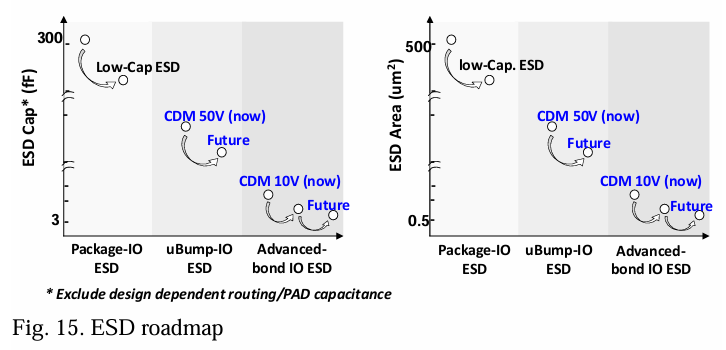
随着行业对更高带宽的追求,ESD结构必须相应地缩小规模,以防止ESD二极管的大尺寸和高电容成为缩放的瓶颈。如果不解决这个问题,将限制IO的能量效率。我们需要为包含微凸点和先进键合的IO制定一项积极的ESD发展路线图。图15展示了ESD电容和面积缩放的趋势[6],还显示了行业支持的充电器件模型(CDM)电压的降低。
电源传输
以UCIe先进封装的10列形态结构为例:在32Gbps操作和0.75伏下具备0.6pJ/bit能效的条件下,基于388.8µm×约1000µm的x64通道模块尺寸,电流密度可以超过4.1A/mm²。在如此高的电流密度下,我们观察到在电源/地凸点上存在严重的电磁(EM)可靠性问题,发现其超过设计规则允许的EM限值三倍。此问题通过更换凸点材料得以缓解,但我们也不得不增加更多的电源/地凸点,并更新UCIe凸点地图以提升可靠性和性能。
此外,UCIe规范支持时钟门控模式。从空闲到任务模式,会引入最坏情况下的动态电流变化率(di/dt),导致显著的电压下降。这会因为定时和电压裕度的减少而导致更高的位错误率。最有效的降低di/dt的方法是依赖芯片内或封装上的去耦电容器来抑制噪声波动。去耦电容策略包括,从上到下(参见图16-a):A) 封装上离散去耦电容器(OPD),通常在µF范围内,B) 封装内去耦电容器,例如在硅中介层上嵌入式深沟电容器(eDTC),其电容密度超过1000nF/mm²,C) 芯片内去耦电容器,包括电容密度约为50 nF/mm²的超高密度金属-绝缘体-金属电容(SHDMIM),以及电容密度约为10 nF/mm²的器件电容[29][49]。位于或接近顶层芯片的电容器显示出较低的串联电阻,但电容密度也较低。随着距离顶层芯片的增加,串联电阻也增加。因此,在确定最佳去耦电容策略时,必须考虑技术、成本、面积和噪声规范等多种因素。
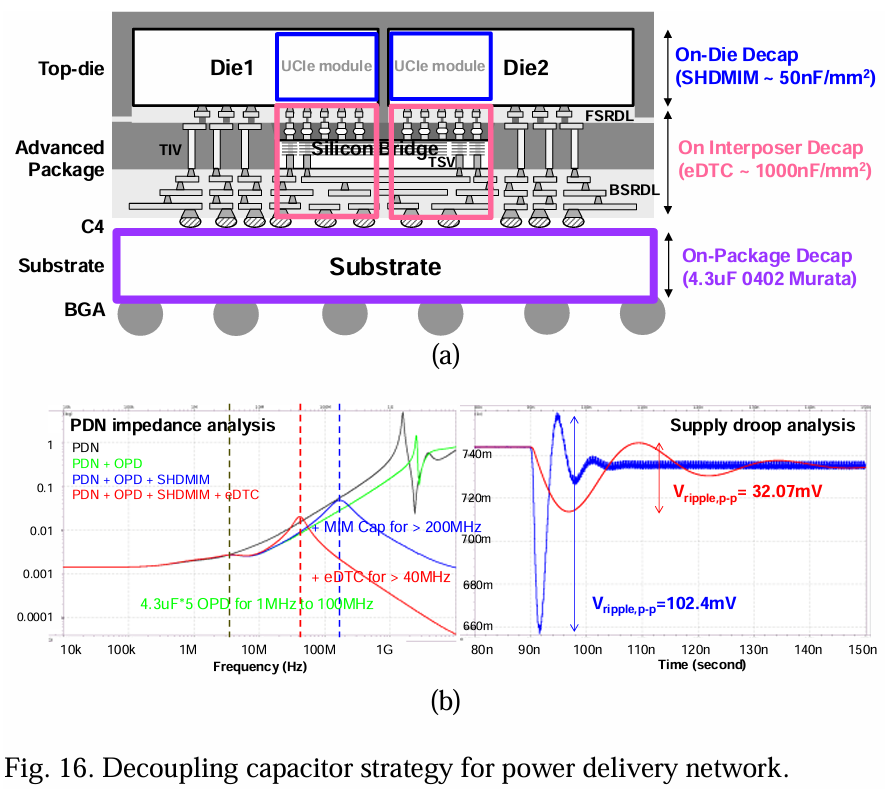
全面的3DIC设计流程
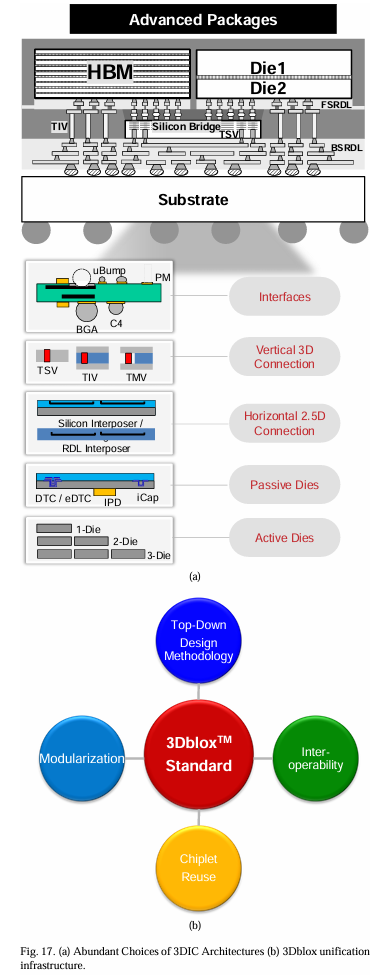
如图17-a所示,先进封装架构涵盖多种封装选项。这些选项包括在每个层级上不同数量的芯片,以及引入各种被动器件,如深沟电容器(DTC)和集成被动器件(IPD)。该架构还支持不同类型的水平连接,包括硅中介层和有机中介层,以及各种垂直连接,如硅通孔(TSV)、中介层通孔(TIV)和模具通孔(TMV)。此外,提供多种接口类型,包括先进键合、微凸点、C4凸点,以及不同的堆叠方向,如面朝下、面朝上、面对面和面对背。
在单一或多个供应商中提供的多样化封装技术,以及众多可能的组合,显著复杂化了设计过程。此外,各种物理集成和验证任务需要不同的EDA工具,需要涉及多家IP和工具供应商。当前的EDA工具、工作流程和方法论已显著演变,以满足复杂3D集成的需求。
为解决3D-IC设计中的挑战,3Dblox™开放标准[60]已经建立并获得广泛的行业认可。如图17-a所示,3Dblox™引入了一种模块化方法,其中3D封装中的每个物理组件被分类并抽象为特定模块。设计3D系统涉及通过实例化这些模块,用高级编程语言创建相互连接的对象,类似于传统SoC的层次结构。
图17-b展示了3DBlox的关键特性。为了简化设计过程,我们将断言直接集成到语言中,实现了一种自上而下、通过构建设计正确的方法。层次实例化功能增强了小芯片的重用,促进了设计效率。随着主要EDA供应商和半导体制造商采用3Dblox,小芯片集成变得更加无缝且显著更高效,得益于改进的互操作性。这种集成将进一步加速3D-IC生态系统的发展和成熟。
未来发展趋势
设计模块化
为支持从4到32 Gbps的数据速率的高级封装,已经定义了六种UCIe形态结构[11]。图18 (a)展示了一种形态结构的示例。考虑到各种焊接点间距、列数、数据速率和技术节点,知识产权(IP)的开发变得耗时且资源密集。为缓解这一挑战,实施了一个模块化概念和编译器兼容方案,如图18 (b)所示。
在这种方法中,芯片到芯片互连被分割为可重复的模块,如IO通道,以及常用的共享模块,包括DLL、PLL、DCDL和校准电路。特定的布局元素,如时钟树,可以根据不同的目标规格进行定制和编译。

带宽和能效扩展
带宽密度和能效仍然是下一代小芯片互连的重点。
封装凸点间距和技术节点对带宽密度有显著影响。图19展示了基于实际工艺和封装技术缩放因子的第一估算的区域带宽密度趋势。为了增强带宽密度,可以提高链路数据速率和/或减小互连凸点间距。然而,更高的数据速率需要更强的电路驱动能力和校准,导致更大的电路面积。因此,可能需要调整凸点间距。例如,在N7技术中,45µm的凸点间距(P45)支持16Gbps,而55µm(P55)和65µm(P65)分别需要用于24Gbps和32Gbps,导致16Gbps以上的区域带宽密度下降。相比之下,N4/N5(4nm/5nm)技术支持数据速率高达24Gbps的增加带宽密度。N3允许进一步增加带宽。设计和技术协同优化可能会略微修改趋势线,但总体上,更先进的技术如N3(3nm)提供了实现更高区域/海岸线带宽密度和能效的优势[61]。
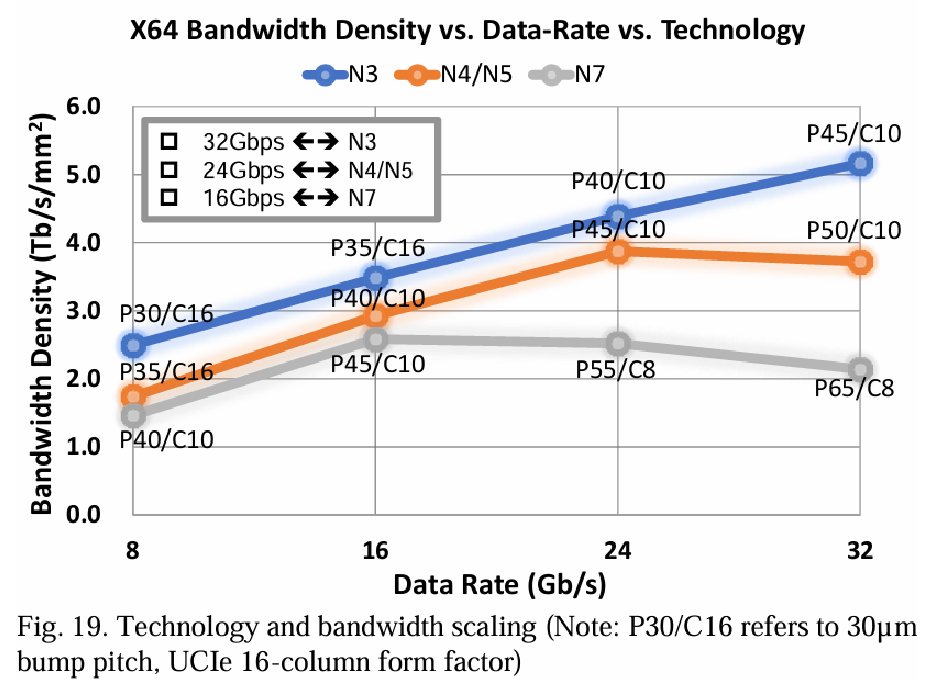
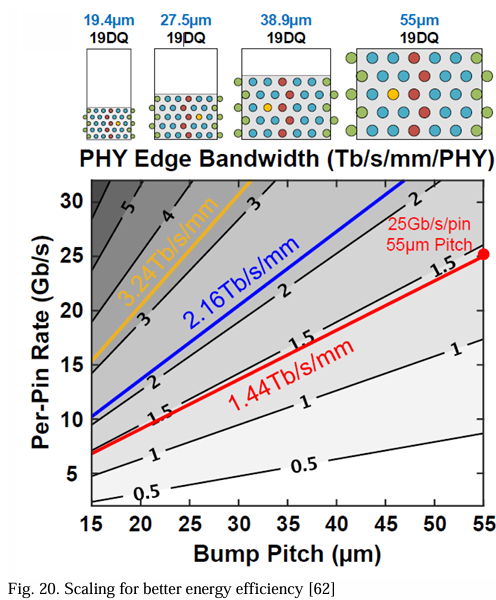
从海岸线带宽密度的不同视角来看,上述研究是基于UCIe凸点映射约束的,结果是较高的数据速率与较高的海岸线带宽密度相关。这与[62]中的评价形成对比,其同时考虑了x和y方向的间距缩放。随着数据速率缩小凸点间距,同时保持凸点限制的情况,海岸线带宽密度保持不变。在这种情况下,由于电路复杂性减少,较低的数据速率预计会提高能效。反过来,技术缩放可以在给定的凸点间距支持更复杂的设计并提高数据速率,从而改善海岸线带宽(例如,从1.5提升到2 Tb/s/mm),如图20所示。
更大的系统
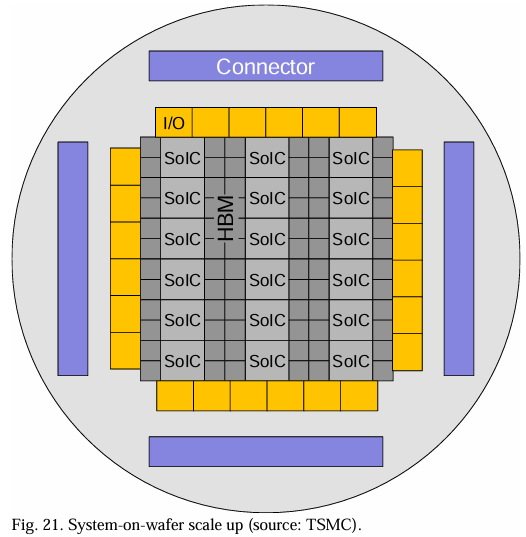
由于光罩尺寸限制,AI/ML开发的最新趋势是在晶圆级扩展(图21)[13][14][15]。通过结合由3DFabric(或同等技术)提供的解决方案,我们可以有效地利用SoIC进行SRAM+CPU和HBM+GPU的集成,利用LSI进行CPU+GPU(高密度/近距离)的集成,利用LSI进行xPU到I/O芯片的集成,使用被动LSI用于eDTC(用于封装内去耦以减轻电源噪声),以及使用RDL进行电源传输和大规模集成中的长距离数据传输。这种晶圆级封装减轻了光罩尺寸限制带来的约束,同时在不久的将来需要网络级晶圆[13][14]以及异构(串行和并行)[18]或混合(光和电)连接[63]以实现xPU到xPU的高效互连。
在晶圆级封装之外,扇出型面板级封装(FOPLP)[64][65]也在前景中,预计在面板级封装中实现更高的封装吞吐量、降低成本和潜在的更大集成系统,其中翘曲控制在整个封装过程中仍是一个重要挑战[66][67]。
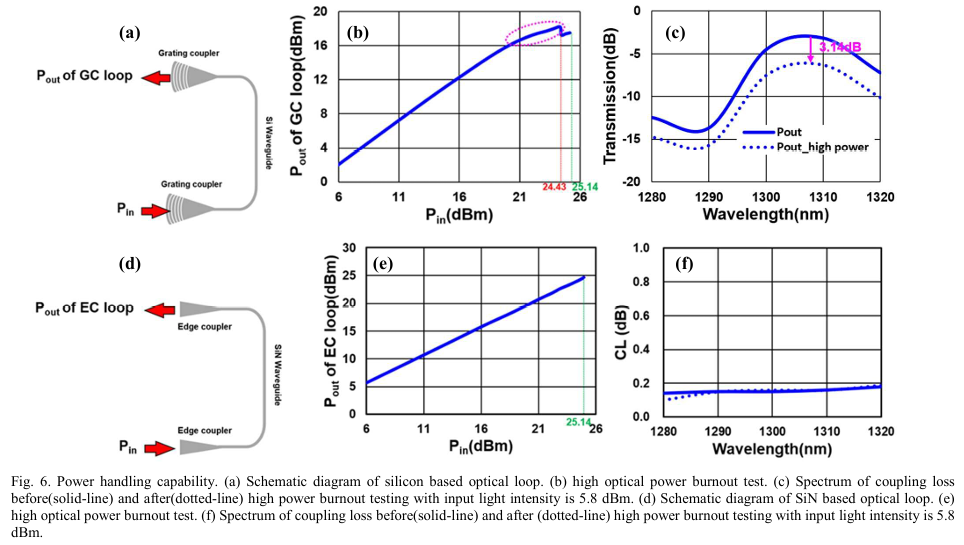
与此同时,对更高互连数据带宽密度的渴望持续增加,例如,UCIe联盟正在研究一种用于芯片间互连的48/64Gbps提案。对于系统的扩展和扩散,封装内光波导[68]和共封装光引擎[69]继续吸引着行业的关注。
更大的系统需要具有集成磁组件的垂直电源传输,以实现高效的电压调节[70][71]。更大规模的CPU、GPU、HBM、SerDes、光引擎和电压调节器的集成是一项重大工程,超越了一些现有的工程壮举[13][14][15]。实现这一目标需要各行业合作伙伴的协同努力,以管理技术堆栈的不同方面,确保在实现高性能的同时,确保卓越的能效、信号完整性、热管理和结构稳健性。
随着小芯片生态系统的日益成熟和3D-IC设计方法的进步,新的可能性和更伟大的创新将会涌现。